|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Site Map |
Contact Information:
Dr. Keith A. Markus
kmarkus@aol.com
212-237-8784
Room 2127N
Psychology Department, John Jay College
Jess Saunders (Teaching assistant)
646-284-6097
jsaunders@jjay.cuny.edu
Course Description: The course builds on the introductory survey provided in Quantitative Methods I (CRJ U70200) focussing specifically on linear regression methods for a variety of different kinds of data and research questions. The course reviews basic regression and moves quickly on to more detailed consideration of specific issues in the use of regression. These include, regression assumptions and diagnostics, curvilinear relationships, interactions, categorical predictors, multiple dependent variables and systems of equations, basic introduction to path analysis and structural equation models. The course involves use of archival data sets and data analysis using SPSS and Mx software.
Objectives: By the end of the course, students should aim for the following.
Required Software:
SPSS: You will need to
complete
homework assignments using SPSS for Windows. It does not matter
which operating system (Windows, Mac, etc.) that you use. Avoid
the student version because it cannot handle large data sets. I
have ordered the SPSS
Graduate pack through the bookstore. This is fully
functional,
but available only to graduate students. You can also use SPSS in
campus computer labs. (Note that campus machines run an older
version of SPSS that cannot read SPSS output files, SPO files, from
newer versions. It can read SPSS data files, SAV files. So
you may want to form a habit of saving output in HTML format.)
Mx: You will also need Mx software for structural equation modeling. The price is right. You can download this software for free from the Mx Home page (http://www.vcu.edu/mx/). I will try to make Mx available at some campus computer labs.
Required Data:
Homework
assignments will use the following data set: ICPSR Study
#6787. I recommend that you download the codebook (pdf), data
(text), and SPSS setup (text) during the first week of classes.
You may encounter difficulties and need to ask for
help. Please come to Jess or myself for help before contacting
anyone else. Simply type '6787' into the search window on the
ICPSR Web page. If you have not, you may need to register a
username and password before you can download files. I recommend
changing the name of the data set from da6787 to da6787.txt and
changing the name of the SPSS syntax file from sp6787 to
sp6787.sps. Once you download the files, which will come as zip
files, you will need to unzip them. Once you do that, you should
open SPSS and use it to open the setup file in the SPSS syntax
window. You will need to edit two things. First, replace
'physical filename' with the correct path and file name for your PC (it
depends on where you saved it). You can save some typing by
copying and pasting this from the window that you use to view files and
folders on your PC. Second, you need to add 'execute.' to the end
of the file. Do not forget the period. Once you make these
changes, choose 'all' from the 'run' menu. After some blinking
and
whirring, the data should appear in the data window. Once you
have read the data successfully, use the variable view window to enter
the missing values listed in the variable labels column. You can
do this selectively because we will not need all the variables.
Alternatively, you can do this using SPSS syntax in the syntax
window. Save the data set as an SPSS SAV file to save yourself
the trouble of having to repeat this process.
Course Flow: Familiarize yourself
with the reading material before the corresponding lecture.
Lectures
will summarize and clarify the reading. If you have questions
about
the reading, come prepared to ask them in class. General
questions
about the homework can be discussed at the beginning of class, specific
problems are better discussed outside of class and particularly in the
lab. I will demonstrate statistical
analyses in class. Homework and lab time will provide
opportunities
for practice with SPSS and Mx.
Lab: Plan on attending
lab sessions regularly. This offers your first and best
opportunity to get help with homework assignments in a timely
fashion. You will also benefit from a second opportunity to ask
questions and review the material from the lecture.
Examinations: The examinations will not be cumulative but later material will always presuppose a familiarity with prior material. Content of the examinations will reflect the course objectives and will not be limited to computations. You are allowed one 8.5 x 11 inch hand-written page of notes and a calculator to be used during each examination. Examinations will emphasize your ability to reason using statistical principles studied in the course.
Homework: You will need to run examples using SPSS or Mx and turn in printed output to demonstrate that you have done this. As such, you need to have a PC capable of running SPSS and Mx, access to the World Wide Web, and a printer. I understand that this represents your first pass at the material, so homework assignments will be graded more for completeness than accuracy (not true of examinations). Homework is also an early warning system to help you evaluate your own understanding of the material. Do not get behind in the homework. As a general rule, once you fall behind in a quantitative methods course you will find it hard to catch up. So, if you find yourself slipping behind, talk to me right away.
Grading: Each of the two examinations
is worth 30% of
your total grade. That leaves 40% for the homework
assignments. Letter
grades will be assigned as indicated below.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Course overview. Review of key concepts regarding data analysis, statistics, and research design. Some scaling theory basics. Theories and models. Downloading data sets from ICPSR and elsewhere. | |
| M
9/5 |
Class
does not meet. |
|
|
|
Chapter 1: Introduction. Chapter 2: Bivariate Correlation and Regression. Review of some basic bivariate concepts and techniques. Some new contexts for thinking about these techniques. Statistical inference. Using SPSS. |
|
|
|
Chapter 3: Multiple
Regression/Correlation With Two or
More Independent
Variables.
Conclusion of review of basic regression concepts. Regression models and causal models. Power analysis. |
Homework Assignment 1 (HA1). |
|
|
Chapter 4: Data Visualization,
Exploration, and
Assumption Checking.
Graphical data analysis. OLS regression assumptions, how to violate them, how to recognize when you violate them, what difference it makes, and how to avoid violating them. Why you can run a regression analysis in a minute but need more time to actually complete one. |
HA2 |
| M 10/3 | Class does not meet. | |
| M 10/10 | Class does not meet. | |
|
|
Chapter 5: Data
Analytic
Strategies Using
Multiple Regression/Correlation.
Interpreting multiple-regression output. Using hierarchical regression to test multivariate hypotheses. Alpha inflation, its discontents and remedies. Problems with stepwise regression techniques. |
HA3 |
|
|
Chapter 6: Quantitative Scales,
Curvilinear
Relationships, and
Transformations. What if the effect of one more unit of an IV depends on how much you already have? How linear regression models nonlinear relationships. Interpretation problems and solutions. Data transformations. |
HA4 |
|
|
Chapter 7: Interactions Among
Continuous Variables.
What if the effect of one more unit of an IV depends on how much you have of another IV? Estimating and interpreting interaction terms. Probing interactions. Understanding polynomial regression as a special case of interaction. How to get two different results by analyzing the same data different ways and how to make sense of the situation. |
HA5 |
|
|
|
|
|
|
Chapter 8: Categorical or Nominal
Independent
Variables.
What if I have categorical IVs? Coding schemes for categorical variables. One variable, many representations. Interpreting regression parameters with categorical variables. Regression assumptions with categorical variables. |
HA6 |
|
|
Chapter 9: Interactions With Categorical
Variables.
What if the effect of one more unit of an IV depends on the value of a categorical IV? Categorical variable interactions. Interactions with more than two variables or more than two values. Interactions between continuous and categorical variables. Probing interactions again. |
HA7 |
|
|
Chapter 10: Outliers and
Multicolinearity. How outliers can bias regression results. How outliers can not bias regression results. Diagnosing outliners. Dealing with outliers. Multicolinearity. Diagnosing Multicolinearity. Dealing with Multicolinearity. Representing the same data different ways. Representing the same model different ways. Testing the same theory different ways. Imperfect models. |
HA8 |
|
|
Chapter 11: Missing Data.
Missing data. A problem best solved through prevention. Types of missing data. Missing versus messy. Snatching defeat from the jaws of victory with messy data. How missing data can bias regression estimates. Dealing with missing data. |
HA9 |
|
|
Chapter 12: Multiple Regression/Correlation
and Causal
Models. Regression models and causal models revisited. More than one DV, more than one equation. Recursive and nonrecursive models and why we call them that. Identification and estimation of path models. Testing the fit of the model. Misspecification and its discontents. Using Mx. |
|
|
|
Latent variables. More identification and estimation. How latent variable models adjust for measurement error. How latent variables models can fail to adjust for measurement error. Equivalent models and hypothesis testing. I already feel dizzy and this is just the beginning. |
HA10 |
|
|
|
Turn in homework assignments at the beginning of class on the
days
noted on the schedule. If you encounter difficulty with a written
assignment, ask questions in the lab. If you still cannot figure
it out, contact me with your question. For all assignments, turn
in both the output and your written comments. All assignments
refer to
the data set provided for use in the course.
Use the ISPCR 6787 data and documentation described above. Review the portions of the code book that describe CALLRESP, ENFLAW, PEACEKPG, SPRTVCTM, VCTMASST, and LESATISF, including the descriptions of how the researchers formed scales out of individual items. Look at the wording of the individual items on the survey reprinted in the code book. Run a matrix scatterplot of all six scales. Double click to enter chart edit mode and use Options from the Chart menu to add a Lowess line. You may find it helpful to click a Lowess line and use the crayon tool button to change the color. Run a bivariate correlation matrix for all six variables. Give a brief description of the main features of the output. Identify the results that stand out and describe what they tell you about the data.
Run a linear regression with LESATISF as the dependent variable. Enter CALLRESP, ENFLAW, PEACEKPG, SPRTVCTM, and VCTMASST as predictors in the equation. Request the confidence intervals, descriptive statistics, and the correlation matrix in addition to the default statistics. Note the differences between the bivariate correlations and regression weights. Write a paragraph interpreting the results with respect to the effect sizes and statistical significance of each predictor.
Run descriptive univariate statistics for the following variables: CALLRESP, ENFLAW, NLE, PEACEKPG, Q55CITYS, SPRTVCTM, VCTMASST, and LESATISF. Use the SPSS Explore command to request descriptive statistics and stem-and-leaf plots. (Make sure that you have entered the missing values for these variables.) Scan the output for variables with low variance or highly non-normal distributions. Write a short description of your interpretation of the results that identifies any potentially problematic variables.
Rerun the regression analysis from HA2.
This
time, save the unstandardized residuals. Also, request a
Durbin-Watson test. Rerun the scatterplot matrix but add the
residuals as a seventh variable. Add the Lowess lines.
Interpret the result of the Durbin-Watson test and describe any results
in the scatterplot matrix that suggest potentially problematic
relationships between predictors and residuals.
Compute ENFLAW2 as the square of ENFLAW and
ENFLAW2C as the square of centered ENFLAW. (Use Descriptives to
get the mean and type it into the compute command. Do not round
it off.) Run a correlation matrix of these three variables and
verify that centering reduces the correlation with ENFLAW.
Describe the results. Then, run a hierarchical regression
analysis predicting LESATISF from ENFLAW (step 1) and then both ENFLAW
and ENFLAW2C (step 2). Make sure to request the R^2 Change
statistics in addition to confidence intervals. Run a scatterplot
of LESATISF by ENFLAW and add a Lowess line. Interpret the
results. Relate the numeric results to the Lowess line.
Compute CALLENFL as the product of centered
CALLRESP and centered ENFLAW. Run a hierarchical regression
analysis predicting LESATISF from CALLRESP and ENFLAW (step 1) and then
from CALLRESP, ENFLAW, and CALLENFL. Request R^2 Change,
confidence intervals, descriptives and correlations. Interpret
the results with respect to the interaction between the two predictor
variables.
Look at the sections of the code book that
describe the following variables: BLACK12, BLACK27, HISP12,
HISP27, OTHER12, OTHER27, WHITE12, WHITE27. Run a linear
regression predicting ENFLAW from the above variables, omitting WHITE12
and WHITE27. Inspect the bivariate intercorrelations between the
variables and describe any patterns that stand out. Interpret the
results of the regression and, in particular, describe the effects of
any predictors that reach statistical significance. Describe the
direction and size of any such effects.
Review the code book for items Q26 and
Q31.
Run a linear regression predicting LESATISF from respondent age (Q26)
and whether or not the respondent identified his or herself as a
student (Q31). Add an interaction term in step 2 of a
hierarchical regression. Remember to center age before computing
the interaction term. Plot a scatterplot with LESATISF on the y
axis, age on the x axis, separate plot characters for students and
nonstudents, and separate Lowess lines for each of the two
groups. Interpret the results.
Rerun the regression analysis from HA2.
Request colinearity diagnostics and casewise diagnostics and save the
unstandardized residuals, Leverage, DFFITS, Cooks's D, and
DFBETAS. Examine the colinearity and casewise diagnostics in the
output. Run descriptives on the saved variables and examine these
(particularly the maxima). Plot the residuals against the various
predictor variables. Describe the results with respect to
potential problems with the analysis.
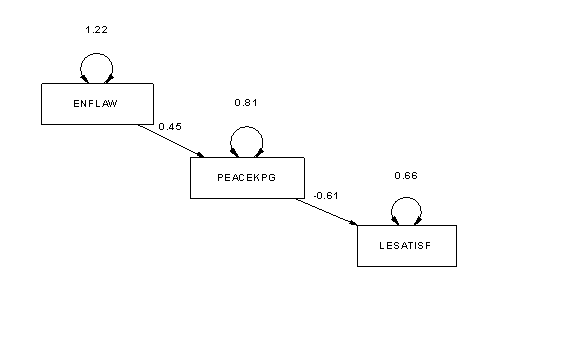
Test a path model in which ENFLAW causes
PEACEKPG
and PEACEKPG causes LESATISF. Use SPSS to compute
the covariance matrix. Save the covariance matrix as a text file
for use as data by Mx. With only three variables, you will
probably find it easier to retype the covariance matrix than save it
directly from SPSS. You can use Mx, WordPad, or any word
processor to edit and save a text file. Your data file should
look like this.
Test the causal chain using Mx by drawing a path diagram, mapping the data, and then estimating the model parameters. Draw the diagram using the tool buttons on the tool bar after clicking the new diagram button. Map the data by opening your data set using the map data tab, and then, one by one, clicking the box and the variables name, and then the map option inside the map data box. Estimate the parameters by clicking the run button inside the diagram box. Click the project manager button to view the expected, observed, and residual covariance matrices. Click the text output tool button from the main Mx toolbar to view the text output file. Turn in the output file (file output on the output menu) and a brief interpretation of the results. Consider the chi-square, RMSEA, parameter estimates, and residual covariance matrix in your interpretation.